In a half-day workshop organized by the Expert Group Smart Services on March 28, participants from seven different organizations (data science, tech, sensoring systems, insurance, service design) came together to explore effective strategies for managing risks of operating industrial assets. The workshop focused on various aspects of risk mitigation, including preventive measures, impact reduction, and decision-making processes.
Preventing risks before they occur is crucial for maintaining a secure and efficient business environment of industrial assets. Our discussions highlighted the preventive measures primarily by technical solutions. Leveraging technology, such as sensor-based monitoring systems, enhances risk detection and early intervention. By proactively identifying potential threats, organizations can prevent adverse outcomes.
However, technologies for preventive and reactive measures open the door for prescriptive measures. This can result in optimizing the performance of an asset over its lifecycle. In this manner, risk mitigation expands into a broader context of asset value optimization, while insurance adopts the perspective of investment optimization. Departing from the conclusion of the predecessor workshop in August 2023 (https://databooster.ch/databooster-workshop-managing-financial-risks-of-smart-services/), the discussion moved to the question of the extent to which technical solutions are scalable or have to be developed from scratch for each application case. We concluded that certain verticals can be effectively standardized for scalability, while others remain within the realm of specialized solutions.
The Expert Day on March 19, 2024 was held for the first time at the University of Applied Sciences and Arts Northwestern Switzerland (FHNW) in Brugg-Windisch. Welcoming over 40 participants, the event enfolded plenty of opportunities for engagement within the three Expert Groups: ‘Smart Maintenance’, ‘AI in Finance & Insurance’, and ‘Spatial Data’ as well as the Expert Group in planning ‘Governance for Growth with Data & AI’. For those interested in joining the latter group, please contact us at info.office@data-innovation.org.
The event started with two thought-provoking keynotes. The first ‘Eyes on Human-Data Interaction’ by Prof. Dr. Arzu Çöltekin, FHNW, highlighted how eye movement tracking can enhance human-computer interactions, emphasizing the importance of designing data-based products with the end user in mind. The second keynote, ‘Lessons learned on scaling after 1 year of GenAI’, by Dr. Marcin Pietrzyk, co-founder and CEO of Unit8, shed light on the significance of GenAI and its mostly underused potential in realizing value in production at scale. A fact that the data innovation alliance wants to address together with the Innovation Boosters Artificial Intelligence and Databooster, powered by Innosuisse.
Following the keynotes, participants engaged in four breakout sessions, each focusing on a specific topic. The following paragraphs will give you a short insight into the different breakout sessions.
Workshop ‘The Future of Financial Data Analytics’ by Expert Group AI in Finance & Insurance
The Expert Group meeting jointly organized by Marc Vendramet, Andreas Blum from Unit8, and Branka Hadji Misheva from BFH, delved into two primary topics. Firstly, it offered a comprehensive exploration of AI & analytics use cases within the finance sector. Secondly, it involved brainstorming on the group’s focus areas for the upcoming year, including discussions on new event formats and collaborations.
Highlights were talks by Nicole Königstein of Wyden Capital, who shared insights on financial times series prediction in the age of transformers, and Guillaume Raille from Unit8, who presented various examples of LLMs’ use beyond chatbots, along with a detailed discussion on the challenges and opportunities associated with applying advanced LLM technologies to real-world cases.
Workshop Governance for Growth with Data & AI
Participants of this workshop gathered to delve into the full spectrum of Governance and Growth theme, as well as the opportunities with Data & AI. Frank Seifert, from adesso Schweiz AG, introduced a comprehensive management model for Governance, while Dr. Omran Ayob, from SUPSI, delved deep into the critical aspect of explainability in data governance. Participants engaged in lively discussions about the challenge of achieving higher data or model transparency (Explainability) while avoiding privacy issues.
The tension between the desire for a minimum level of governance and the need to work simply and leverage Data & AI opportunities became apparent. On one hand, holistic approaches are necessary, but on the other hand, there is a need for concrete, easily implementable measures. It’s precisely this tension that makes the topic so intriguing.
The group will continue working in this area by examining various layers of the topic, especially legal, technical, and ethical aspects, and developing Governance approaches and impulses for Growth opportunities. Our current vision includes guidelines and processes on one hand, and concrete tips and tools on the other.
Workshop ‘Hybrid approaches to intelligent maintenance’ by Expert Group Smart Maintenance
First, Dr. Kai Hencken from ABB corporate research started with an overview of predictive maintenance strategies at ABB, emphasizing the utility of traditional statistical reliability models in addressing data scarcity challenges.
After, an open discussion among participants followed, exploring potential use cases for AI integration with domain knowledge in their respective companies. Examples included condition monitoring of trains and digital twins for gas turbines. Technical solutions such as few-shot learning and the role of LLMs and generative AI in advancing condition-based and predictive maintenance were also examined.
The day concluded with an Apéro, fostering further discussions about innovative ideas among participants. We are already looking forward to the next event, as we are convinced that together we move faster.
The event “AI’ll be back – Consequences of AI regulation for startups”, jointly organized by the Data Ethics expert group and Technopark, generated a great deal of attention. More than 40 persons listened to the speakers and discussed lively on how the emerging regulation of AI may affect innovation.
The use of artificial intelligence in the EU will be regulated by the AI Act, the world’s first comprehensive AI law. Its purpose is to documentation, auditing, and process requirements for AI providers. What does that mean for AI startups in Switzerland? This question was the focus of an event organized by the Data Ethics expert group of the Data Innovation Alliance. More than 40 persons attended this meeting on Thursday, February 1, at the Technopark Zürich.
First, Livia Walpen, Senior Policy Advisor International Relations at the Federal Office of Communication (OFCOM), outlined the current state of the EU AI act and its possible consequences for Switzerland. The EU AI act will create a harmonized legal framework for the EU’s internal market. It will be relevant both for private and public actors. The core intention is to classify AI systems according to the risk they involve; depending on the risk, different measures will follow – from no obligations if the risk is minimal, up to prohibited practices if the risk is unacceptable. For practical applications, the main relevant difference will be between “limited risk” and “high” risk – as for latter, various obligations will follow: Among others, those involve adequate risk assessment systems, data sets of high quality, and appropriate human oversight measures. High-risk AI systems will require a registration in public EU databases and providers outside the EU need to appoint an authorized representative in the EU. The AI Act will apply two years after its entry into force, i.e. in 2026 (with the exception of certain specific provisions).
For Switzerland, the new EU AI act will have consequences for all Swiss companies and research institutions operating in the EU, as they will have to assess the conformity of their products in accordance with the conditions or procedures laid down. The AI act might also have an influence on the Swiss political debate and the Swiss regulatory approach to AI. In November last year, the Federal Council gave the mandate for the elaboration of an overview of possible regulatory approaches to AI in Switzerland. The OFCOM, in close cooperation with different federal offices, is currently preparing a report that will outline different possible approaches for Switzerland, to be published by the end of this year.
Christoph Heitz, Founder and President of the Data Innovation Alliance, discussed how developers of AI applications in companies need to prepare already today, how the AI Act changes the job of developers, and how startups can obtain support for these new challenges. His main message to the audience consisted in three points: First, know what your AI application is actually doing. Second, AI regulation leads to innovation challenges; i.e., new solutions are required. Third, there is support for helping companies to master the transition. As for the last point, he pointed to the “Innovation Boosters” run by the Data Innovation Alliance: The already estabilshed “databooster” and the new Booster “Artificial Intelligence”. Both booster programs support companies in developing innovative approaches to address the regulatory challenges for their concrete AI products they aim to develop.
Finally, Christoph Bräunlich, Head AI of BSI Software, presented a use case to demonstrate how a “Code of AI conduct” can help to be prepared for compliance for AI regulations. He outlined how BSI has developed a “Code of Conduct AI”, inspired by the “Code of Ethics for Data-Based Value Creation” of the Data Innovation Alliance. A key element of their Code of Conduct is the role of an “Ethics Enabler” – a person within the company that structures discussions on ethical issues of a specific AI innovation within the company. After the three talks – the slides are available as pdf download – a lively discussion emerged in the audience, moderated by Markus Christen, managing director of the Digital Society Initiative of the University of Zurich. Several people pointed to the practical issues that may arise when assessing concrete risks of AI systems – certainly a point where both the regulator and the companies will have to gain experience.
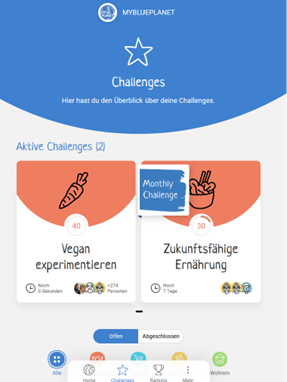
The Expert Group Smart Services had the chance to listen to the presentation by Noah Gunzinger, Managing Director of MYBLUEPLANET. MYBLUEPLANET is a 16 years old Swiss non-profit with the mission to take individual and collective action against climate change. The initiative encourages people to get actively involved in climate protection. Noah presented one of the programs, the Climate Challenge App which offers personalized experiences, ranking comparisons, self-improvement controls and much more.
Key to the android and iOS App is the ability to build teams and participate as a company or a team in the challenges. By regularly updating the challenges on consumption, diet, habitation and mobility and having a common monthly challenge, participants understand that they are part of a bigger movement towards net zero.
The data show that some topics work better than others, for instance dietary topics are more preferred by the users than mobility topics. As of now, there are about 2500 registered users with little churn. Future developments will focus on improvements increasing user engagement.
The presentation was rounded off by a lively discussion with the numerous participants that revolved around the topics of user engagement, measurability, local activities and B2B embedding.
Immersing ourselves in the realm of captivating ideas, gaining firsthand insights into the journeys and lessons learned from innovators, and seizing the opportunity to exchange ideas and network with like-minded enthusiasts – doesn’t that sound exciting? Such was our most recent Project Day on December 14th, 2023, hosted at Oracle in Zurich.
30 enthusiastic participants gathered to hear about a wide range of innovative ideas supported by the Innovation Booster Databooster ranging from data-based battery diagnostics to various projects in the health sector. Participants gained valuable insights into eleven different innovation projects and profited from their lessons learned. The afternoon also offered networking opportunities that sparked new innovative ideas and provided the opportunity to come up with future collaborations.
To dive into some highlights, the project presentations started with the brilliant idea from Schwabe Pharma and OST (Eastern Switzerland University of Applied Sciences) on how to better understand the individual appearance patterns of health issues like Tinnitus. They applied BPM (business process mining) algorithms to health data to analyze the multiple factors influencing tinnitus on an individual level but also to improve our general understanding on the health concern.
Another highlight was the presentation of the inspiring innovation project from leg&airy and how they aspire for fair human mobility by revolutionizing the world of orthopedic devices. Leg&airy follows the idea of using digital fitting and data-driven design to predict optimal orthotic fit to avoid painful pressure injuries, improve mobility, while enhancing patient privacy by automating the customization process.
Fluence Energy and ZHAW presented their project “AI-Based Health Prognostics for Battery Energy Storage Systems” and shared some valuable advice for a successful journey from a Databooster funded idea that led to an Innosuisse funding for the upcoming year.
The diverse array of projects showcased the power of collaborative innovation and the transformative potential of data-driven solutions. It was inspiring and valuable spending an afternoon to learn from other innovators, discuss radical innovation ideas and connect for future collaborations.
Thank you to the eleven innovation teams that shared their projects, provided some learning opportunities and sparked new ideas: bodenproben.ch, BFH and ZHAW, DNext and HESSO Geneva, Fluence Energy and ZHAW, leg&airy and ZHAW, modulos and ZHAW, opensource.construction, SUPSI and ZHAW, Carity, ZHAW and hospitals, Schwabe Pharma and OST, Stadler Rail and ZHAW, as well as zubischuhe and ZHAW.
And of course, thank you to the participants for their active engagement!
In its end-of-year-meeting, seven members of the Data Ethics Expert Group came together for discussing potential innovation projects in Responsible AI. Both researchers and industry representatives discussed the question: “What do we see as the biggest challenge for research / in our company on the way to Responsible AI?” Below you find a short summary of the discussion points.
The “Innovation Booster” is the current vehicle of the data innovation alliance to push new innovative ideas that have potential for new marked solutions or that solve pressing problems in data-based value creation. Christian Hauser (Fachhochschule Graubünden) presented details on how the Booster works based on the example of an ongoing project. This project intends to support decision-making within companies on various ethical and legal aspects of making business with data.
In a next short presentation, Frank-Peter Schilling (ZHAW) presented activities of the new Center of AI. A focus of ongoing activities concern certification of AI – an issue that will gain relevance due to the upcoming EU regulation of AI. They address the question of how to implement AI systems evaluation at the technical level for high risk AI. This is a pressing topic of various actors such as ISO, IEEE, EASA and the German Fraunhofer Institute. The goal of an ongoing Innosuisse research project carried out at the Center for AI in collaboration with CertX AG is to establish a workflow that should support the certification process.
Another domain where new challenges may emerge is the Metaverse. Eleonora Viganò (Fachhochschule Graubünden) presented the raising trends that companies create own “metaverses” or aim for being present in the larger existing metaverses. Although these developments are still young and diverse, it is foreseeable that the economic relevance of the Metaverse will raise, although many legal and ethical issues remain unsolved. Her research aims to develop guidelines for desirable behavior in the Metaverse such that companies do not risk their reputation in this new domain.
Christoph Hauser (University of Applied Sciences Luzern) presented the topic of how generative AI may affect the generation of cultural assets, a highly relevant topic for the creative industry. Again, many unresolved legal and ethical issues, e.g. related to copyright or liability, may have an impact on the use of this technology. The presentation triggered a lively discussion, pointing to the fact that some industries (such as banks) internally block the use of generative AI completely to avoid any legal risks, although many use cases would exist. The group came to the consensus that any solution that could make the use of generative AI safer in a legal sense would be of great help for such companies.
Anna Broccard, working on data and digital ethics at SBB, presented ongoing activities within the company – also related to a project of Christian Hauser, where SBB is a partner. The current main goal is to establish suitable internal structures and decision-making processes that incorporate different perspectives and teams to address digital ethics issues.
Daniel Blank (ZKB) pointed to a pressing problem of data driven risk rating – a key process of insurances and bank: nondiscrimination in risk rating. The main problem is here that the application of fairness principles does not necessary guarantee that the result is nevertheless seen as unfair in the public domain – and transparency on which fairness principles were used actually increases the problem. Also this topic generated a lively discussion pointing to the problem that for many such decisions a lack of consensus on applicable fairness within the society generates an inherent reputation risk. One possibility may be to factor in the likelihood of reputation risks in the current risk rating models – but whether this may be a feasible approach would need further considerations.
Finally, Markus Christen (University of Zurich) outlined a project that recently has been submitted for funding. The project aims to make an intercultural comparison on the adoption of AI solutions in various industry domains and education between Switzerland and Ukraine. The goal is to assess how existential threats a country in war experiences affects both assessment and actual use of AI technologies, including those considered “high risk” from the EU legislation standpoint.
The Expert Group will meet again on Thursday February 1 in a public event at the Technopark Zürich (https://data-innovation.org/events/expert-group-meeting-data-ethics-and-responsible-ai/). At this event, challenges of the new EU regulation for startups will be discussed.
(by J. Meierhofer, ZHAW and R. Leiterer, data innovation alliance)
On November 23, 2023, ERNI in Zurich hosted this workshop co-organized by the GEOSummit, the data innovation alliance and the SGPF. The event was a success, with 23 participants from industry, academia, and governmental organisations and with different skills and interests joining the workshop. Jürg Meierhofer (ZHAW) was our moderator and guaranteed a result-oriented and structured course of the workshop.
The workshop dealt with the topic of value generation with open data – with an initial focus on developments in the field of decentralized energy supply.
Creating value based on open data is difficult, as topics such as harmonization of data formats, automatic data lineages or the standardization of data linkage processes are technically challenging and also not unproblematic from a regulatory point of view. But even supposedly simpler steps such as contextualized data search and raising awareness of the availability of open data in general have only been implemented to a very limited extent.
Related to the energy topic mentioned above this includes, for example, the analysis of consumption data collected by sensors and smart meters – or, more generally, exploiting the potential of energy management systems due to the increasing electrification. Especially regarding energy savings (e.g. usage-specific lighting scenarios), these so-called IoT recommender systems have the potential to deliver great added value, for the respective households but also for the electricity providers (e.g. regarding dynamic tariffs). in this context, we discussed topics such as data protection, data infrastructure and data management, open platform ideas for data sharing and trading and the smart services that could be built on them.
In the hands-on session the participants worked in teams to solve these real-world problems with open data. Each team was given a predefined problem related to open data, such as smart grid, smart city, or gamification. The teams had to analyse the problem, identify the best opportunities and ideate the most viable solution. They also had to present their ideas, solutions, roadmaps or action plans to the judges and the audience. The workshop followed the double diamond design approach.
In a first round, the participants explored the problem space by mapping the ecosystem and the relevant actors with their jobs and pains. In the second round, they discussed how these actors can be supported by data driven solutions and services, including quantitatively estimating the business potential of the solution approaches.
The event was a great opportunity to network with other data enthusiasts, learn from experts, showcase creativity and innovation skills, and have fun. The event was followed by a networking session, where the participants exchanged feedback, insights, and contacts.
On November 30, 2023, a pivotal event centered on Natural Language Processing (NLP) in Healthcare unfolded, featuring four expert presentations. The gathering, attended by around 30 participants both in-person and online, sparked vibrant discussions and received positive feedback.
Elif Ozkirimli from Roche illuminated the strategic integration of NLP across the pharma value chain in her presentation, “Adoption of NLP in Healthcare: a Strategic Perspective Across the Pharma Value Chain.”
Matteo Manica from IBM delved into the innovative use of language models to expedite material design in his talk titled “Harnessing the Power of Language Models to Accelerate Material Design.”
Ahmad Aghaebrahimian from ZHAW presented a work in progress, “Medical Informatics Powered by Large Language Models and the Semantic Web,” highlighting the cutting-edge amalgamation of LLM and the Semantic Web in medical informatics.
Nicolas Löffler-Perez from Swissmedic showcased “Medicrawl,” a machine learning-based application designed for detecting illegal products in online markets.
The event was a successful exploring the multifaceted applications of NLP in healthcare, demonstrating innovative approaches and fostering collaborative discussions.
On December 4th, the Data Innovation Alliance Expert Group “AI in Finance & Insurance” met at the Unit8 Zurich office for the third time this year. The meeting united a diverse array of data & analytics professionals and enthusiasts from Swiss financial institutions such as Helvetia Insurance, Swiss Re, Migrosbank and ZKB. The meeting served as a melting pot of ideas and innovations in the realm of Generative AI and its applications in finance.
The Agenda: A Blend of Insight and Inspiration
The event commenced with a warm welcome from Prof. Branka Hadji Misheva and Andreas Blum, setting a tone of collaborative inquiry and discovery. The agenda was packed with enlightening talks, starting with an engaging presentation by Benjamin Theunissen from Helvetia Versicherungen. Theunissen illuminated the audience with Helvetia’s approach to Generative AI, highlighting their groundbreaking projects ClaraGPT and Helvi, designed for external and internal customers, respectively.
Prof. Branka Hadji Misheva then delved into the use of large language models for entity matching in financial data management. Her insights on how these models can capture semantic similarities, bridging gaps in data where keyword overlaps are absent, were particularly enlightening.
Lastly, Thanos Giannakopoulos, senior data scientist and co-lead of the Unit8 Generative AI Practice, captivated the audience with a talk on “GenAI in Action.” His demonstration of how Generative AI can rapidly retrieve information from risk documents was a testament to the transformative potential of these technologies in the financial sector.
The Core Message: Bridging Theory and Practice
A recurring theme throughout the meeting was the underutilization of Generative AI in finance and insurance. Despite its transformative potential, there remains a notable gap in practical implementation. This meeting aimed to bridge that gap, moving beyond theoretical discourse to showcase tangible, real-world applications.
Networking and Future Collaborations
The event concluded with an Apèro, offering attendees a chance to network and engage in deeper discussions. This informal segment was perhaps as valuable as the formal presentations, fostering connections and future collaborations among the expert group members.
Looking Ahead
Our expert group is looking forward to hosting further events in 2024. After a ground-breaking 2023 with GenAI dominating the headlines, we’re all excited about what the next year will bring in terms of further developments and applications in the Generative AI space and also the broader space of AI. Both Branka and Andreas would like to extend a big thank you in particular to the speakers but also all the active expert group members throughout this year.
By Thomas Zaugg, Roche and Manuela Hürlimann, ZHAW
On November 30, 2023, a pivotal event centered on Natural Language Processing (NLP) in Healthcare unfolded, featuring four expert presentations.
The gathering, attended by around 30 participants both in-person and online, sparked vibrant discussions and received positive feedback.
Elif Ozkirimli from Roche illuminated the strategic integration of NLP across the pharma value chain in her presentation, “Adoption of NLP in Healthcare: a Strategic Perspective Across the Pharma Value Chain.”
Matteo Manica from IBM delved into the innovative use of language models to expedite material design in his talk titled “Harnessing the Power of Language Models to Accelerate Material Design.”
Ahmad Aghaebrahimian from ZHAW presented a work in progress, “Medical Informatics Powered by Large Language Models and the Semantic Web,” highlighting the cutting-edge amalgamation of LLM and the Semantic Web in medical informatics.
Nicolas Löffler-Perez from Swissmedic showcased “Medicrawl,” a machine learning-based application designed for detecting illegal products in online markets.
The event was a successful exploring the multifaceted applications of NLP in healthcare, demonstrating innovative approaches and fostering collaborative discussions.