In this edition of the AI Use-Case Talks, on the 30th of August 2021 and the first time live on-site at Technopark in Zurich again in a long time, members of the data innovation alliance from industry, academia and practice discussed predictive maintenance, automated machine learning and structuring information in technical documents.
Dr. Marc Tesch
Our first speaker, Dr. Marc Tesch, CEO and founder of LeanBI AG, used an example of Swiss Post to give participants an insight into Predictive Maintenance. He showcased how suitable sensor technology, IoT and AI can be used to automate the monitoring of installations and machinery to detect errors before they occur.
Dr. Kevin Schawinski
Our second speaker, Dr. Kevin Schawinski,CEO and Co–Founder of Modulos Plc, presented his talk with the mystical title “Automated Machine Learning: from cows to galaxies”. He showed the Modulos platform in action with two use-cases: how Swiss dairy farmers can make better decisions on their farms based on their data, and how astrophysicists use AI to analyse data from space telescopes more efficiently.
Dr. Moritz Platscher
Our third speaker, Dr. Moritz Platscher, Senior Machine Learning Engineer at Acodis Plc., a Winterthur-based start-up focused on extracting structured data from documents of any kind using machine learning methods. He highlights some of their approaches to the challenges that one faces in such heterogeneous datasets and presented examples from a recent use case.
These three interesting AI Use-Case talks sparked a lively and interesting discussion afterwards. In the interesting Q&A session, we exchanged ideas, challenges and information among the industry and academic experts. The discussions were deepened after the presentations over a delicious aperitif.
The AI Use-Case Talks are part of a series that takes place three times a year. If you are interested in sharing your AI stories and discussing them with other industry members, you are warmly welcome to join us for our next Use-Case Talks taking place on 8th November 2021. If you are interested in presenting a Use-Case, please contact us by e-mail (nadine.furrer@aspaara.com).
About the Use-Case Talks
The Use-Case Talk Series allows participants to enjoy in-depth technical discussions and exchange information about interesting technical challenges amongst experts. Two to three industry experts and numerous participants took part in the Use-Case Talk to share stories and insights about frameworks, best practices, and tools in data science.
The Use-Case Talk Series is organized by Aspaara Algorithmic Solutions AG on behalf of the data innovation alliance.
We look forward to seeing you soon!
Alexander Grimm, CEO of Aspaara Algorithmic Solutions AG
The 18th meeting of the expert group “Data Ethics” took place online on June 24, 2021 in the afternoon. We were joined by 8 participants.
Markus Christen started the meeting by informing about the status of the discussion with different Swiss associations about the adoption of the “Code of Ethics for Data-Based Value Creation”. As a specific measure, Swico has created a short version of the Code that will go public soon. The expert group is currently working on use cases to demonstrate applicability of the Codex.
Then the expert group discussed the scheduling of the public event on “AI in Human Resources”. The current plan is to organize the meeting between September and November, based on the availability of the speakers and on the pandemic situation. The Alliance will be informed about the meeting as soon as the availability of the speakers has been clarified.
Of particular interest was the input of two companies – SBB and Mobiliar – on current data ethics practices. Carmela Wey (SBB) demonstrated how SBB used the ethical code as a basis for developing different measures within the data strategy and the analytics strategy. In both strategies, ethical issues are now being addressed, and concrete implementation activities have been started.
Karin Lange (Mobiliar) then outlined how digital responsibility can be implemented in a company as a culture. She explained that, when starting the discussion about data ethics in Mobiliar, privacy and data security issues were broadly accepted, but doing more than this was difficult to accept for many. The situation changed when people realized that data ethics is of central importance in gaining and keeping the trust of the customers. Here, ethical issues beyond the minimum legal requirements are becoming important. Also, Mobiliar used our Ethical Codex as basis for deriving 6 data ethics principles which are now being implemented within the organization. Analogous to the mandatory compliance training, Mobiliar has implemented the mandatory training in data ethics issues, for all employees.
Finally, Markus Christen presented the project of creating a White Paper on Ethical, Legal and Social Issues of Big Data as an output of the ELSI Task Force of the National Research Programme 75 “Big Data” (target audience: policy makers). We are inviting short comments for the White Paper – in case of interest, please contact Markus Christen.
Benjamin Wiederkehr, Interactive Things June 28, 2021
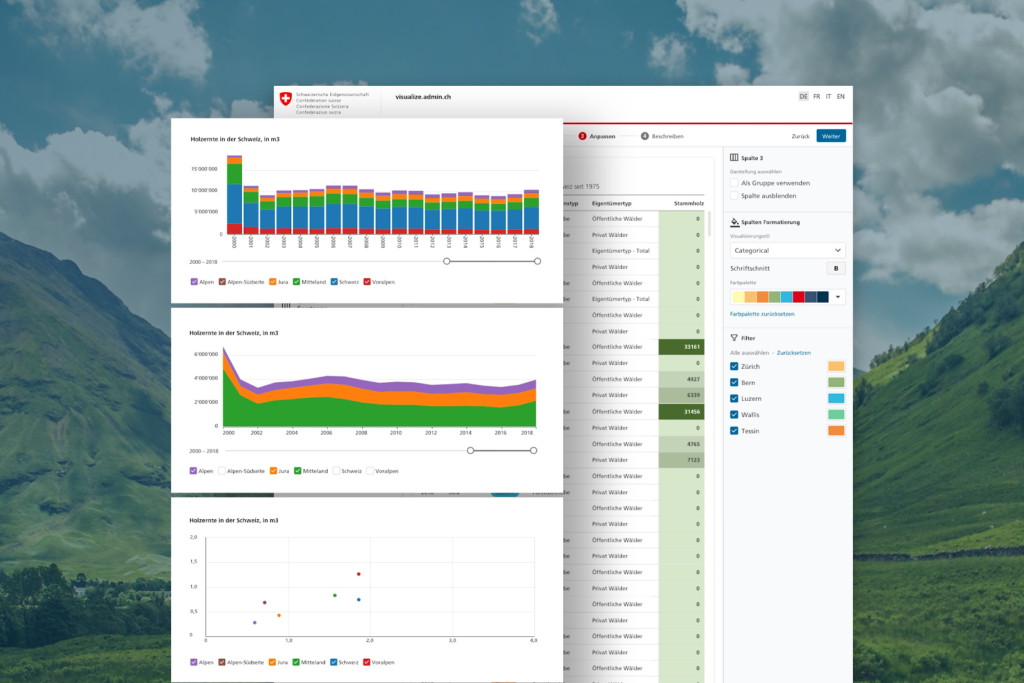
Open Government Data has the power to transform how governments engage citizens. But looking at today’s open data platforms, we have to ask the question of how accessible, usable, and shareable open data for the majority of people truly is?
Turning a downloaded spreadsheet into an insightful visualization requires design expertise. Querying data via an API requires programming knowledge. Sending the link to a data source puts the burden to make sense of it onto the recipient. Users expect from open data to discover facts and tell stories, not to wade through spreadsheets in search of answers. Organizations aspire to provide open data to improve transparency and increase engagement, not to fill a complicated file cabinet with it. Future platforms must lower the barrier to access and bridge the gap to use open data for everyone.
This presentation shares our learnings from building such a platform: visualize.admin.ch. Commissioned and co-created by offices of the Swiss Federal Administration, we envision a new way to better serve citizens through linked open data: a self-service interface that empowers users to visualize open data based on smart defaults and design best practices. Furthermore, the service empowers the user to boost the reach of open data with options to share and embed these visualizations with proper attribution and reliable reproducibility. The audience learned all about the underlying design principles, the impact of participatory development methods, and the benefits of user-centric open data services.
Problem: What makes working with data so difficult?
Organizations maintain a variety of scattered data sources often locked in information silos.
Standard analytics software products might be powerful but are complicated to use for non-technical users.
Results from existing products are un-designed, un-responsive, and un-customizable.
Results from existing products can’t be easily shared in their interactive and dynamic form.
Solution: How does visualize.admin.ch solve these problems?
Access with confidence: Give users secure and regulated access to your data through our unified interface to search and browse the most up-to-date data sets independent of their original information silo.
Visualize for efficacy: Empower users to visualize your data with compelling charts and maps in our intuitive visualization editor that comes with smart defaults and design best practices built-in.
Share for impact: Boost the reach and engagement of your data with our flexible options to share and embed the visualizations with proper data source attribution and reliable reproducibility.
Another year, another successful SDS! In 2021 the data innovation alliance took the bold move to organize a hybrid event. This was a success: in-person participants were very happy to get the opportunity to meet each other in person for more than a year. SDS2021 took place in-person at KKL Lucerne, with the beautiful backdrop of the lake surrounded by the ever majestic Swiss Alps. After a few challenges and some creative solutions, we were happy to be able to host as many as 150 in-person participants and 130 participants online. We could increase the number of in-person participants by making two separate “covid-safe wings”. The participants of the different wings could then get together and interact mask-free by the Lake-side.
All participants could also take part in the conference through the online platform where they had access to the contacts of the other participants in order to share, discuss and maybe even start new partnerships. As networking is an important part of the SDS experience, there were many possibilities for on-site and online participants to interact. For example the hallway discussions took place entirely online in order for the participants to engage there. There was also the opportunity for anyone to start jump-in discussions with a topic of their choice.
The Topics of Interest in 2021 were Smart Services, Learning from Little, Intelligent Data Management, Health and Industry 4.0 as well as many other relevant subjects. We were joined by speakers from Switzerland and Internationally.
SDS2021 in numbers: We had 2 Keynote Speakers, 34 Talks, 6 Sparkle Discussionsand4 streams. 23% participants were from academia and 77% participants from business. 67.5% were alliance members and 32,5% non-members.
But none of this would have been possible by ourselves. A special thank you to our fantastic sponsors with a very special thanks to our presenting partner D ONE and our scientific partner Datalab of Zürich University of Applied Science. And a big thanks to all of our members and volunteers who worked backstage and made sure the conference was running smoothly. Something unexpected is always sure to happen and this year a dog attended the conference. However, due to not having registered in advance and since dogs are not allowed at KKL, he took part mainly from the lake-side in front of the venue.
Outside the KKL
To get back into the SDS mood, see the flashback video here, check-out our photos – maybe you have been spotted! And to spark your memory of the talks – or maybe to see the ones you missed – have a look at the slides and videos.
And what about next year? We hope to be able to use all the experience from the hybrid event of SDS2021 and reuse the most successful aspects.
Save the date for SDS 2022:23rd of June 2022!follow us on LinkedIn and twitter to get the deadlines and to sign-up. See you in 2022 – Together we move faster!
In person meetings have been a rare event over the last months, so coming together to discuss rare events detection for our first face-2-face meeting in over a year, seemed appropriate!
Rare events are a real pain in Machine Learning. How to detect, classify or predict an event you have rarely seen before? These topics are both academically relevant pushing the limits of super computing and machine learning and have industrial relevance in banking, insurance, health and agriculture.
The diverse stakeholder around this topic were well represented in what was an insightful group discussed yesterday in Bern.
Three talks ranging from machine learning methods for financial risk modelling to super computers needed for the physics modelling of natural hazards such as floods and using machine learning to improve predictions, set the scene.
Dr. Thomas Krabichler, OST «Rare Events in Financial Modelling»
Dr. Ralf-Peter Mundani, FHGR «Predicting Natural Hazards such as Floods with Parallel Numerical Simulation»
Dr. Pedram Pad, CSEM «A data-driven approach for lightning nowcasting with deep learning»
Dynamic interaction during the presentations meant the event was already discussing before the apéro started.
Thanks to everyone for the lively debate – Let’s hope more events like this are not rare!
Could you shortly tell us what Zetaminddoes and who you are?
Zetamind is a consulting company. We consult our customers – public administrations and private companies – on data value creation. I, Andre Golliez, am one of the founders of Zetamind. I’m a computer scientist, with a 40-year-long background in IT, in computer science and data. Some years ago I initiated the open data movement in Switzerland. I also work with the politics of data use.
What is Zetamind’s background story?
I and the co-founders Giulia Fitzpatrick and Tom Kleiber founded Zetamind about two years ago. Zetamind is based on the idea that data is a strategic infrastructure and resource for any company, public administration and for the society at large. The motivation to found Zetamind was to consult on the better use of data for it to benefit everybody in the economy and society.
André Golliez, Giulia Fitzpatrick, Tom Kleiber
Now we are a start-up with five colleagues. We are focusing on companies and organizations especially in the German part of Switzerland.
Our customers find us through our excellent network. We have all been in the IT consultancy business for many years and have a strong network. We are also very active in the public sector and in data politics. This way we get a lot of visibility.
Why is it important that Zetamind exists?
Data is important. This is the first point. During all my time working in IT, data was always an important topic. But I really saw a change about 10 years ago, at the time when I started the open data movement in Switzerland. That’s when I learned that data is a resource and that the reuse of data is important. Through the reuse of data, we learn from the successes and challenges.
“What we really see now during the pandemic is that it’s all about the data. The data shows us what we need to know: where the cases are, the incidents and the required health institutions. Data also shows us where the vaccinations are at etc. So, it’s always important to have access to the data as well as reusing it to get a better database which is turn make for better, informed decisions.”
What we really see now during the pandemic is that it’s all about the data. The data shows us what we need to know: where the cases are, the incidents and the required health institutions. Data also shows us where the vaccinations are at etc. So, it’s always important to have access to the data as well as reusing it to get a better database which is turn make for better, informed decisions.
And Zetamind is important because we don’t look at data value creation only from a technical or economical perspective. Our focus is on the reuse of data from a holistic point of view when we look at the capacity and the empowerment of organizations. Companies are used to working in silos – organizational and technical. Zetamind comes in to develop the idea that data use and reuse demands thinking beyond branches: technical, organizational and political. We help our customers generate ideas about data use, to think across borders. We help to think about technical and economic questions (legal, data protection, IP, copy rights) and about ethical questions.
Ethics is important, because many things can be done with data that is not technically forbidden but the algorithm can accidentally be discriminatory – this has, for example, happened in HR department. And this can put the company reputation at risk.
So, in short, Zetamind helps to create strategic governance and the “data use culture”.
Who can profit from your services?
Companies and administrations who want to reap better use of data and to reuse data -the data both from within and outside of your own organization. Most of our customers have data scientists in the organization but they are often limited to a certain area of the organization. This limits the potential of the data.
Data reuse is broad – it’s spanning over all areas of an organization – and long-term it contributes to all the various aspects and dimensions of the organizational culture, also the legal and ethical.
Companies and administrations can profit from our consultancy to establish a data culture for their organization, starting with small projects and use cases. We also do hackathons, which in practice means the open data movement. Hackathons are a really a great innovation approach that can be done with a small budget. It mobilizes a lot of ideas, a lot of people and gives very valuable results with only a few hours or days of engagement. We have gotten great results with hackathons on different levels.
Can you give some examples of your success stories?
Both my personal – and Zetamind’s – success is the open data movement. I think the development of the open data movement in Switzerland shows this.
“And I thought, okay, this (open data) is interesting, I want to know who is doing something in Switzerland on this and I learned that nobody did! So, I decided to start it.”
When we started this, it was a very special thing. I learned about open data in 2010 at a conference in Geneva and at the time I knew nothing about it. We were told about open government data from the USA – this was during the Obama era. And I thought, okay, this is interesting, I want to know who is doing something in Switzerland on this and I learned that nobody did! So, I decided to start it. I found colleagues from the open-source movement and connected them to the open data movement and together we started to act on a political level. 10 years later we have an open data platform at the federation and a first concept and implementation of an open government data platform.
What are your biggest challenges?
The consciousness, I think. Telling about data reuse and how to approach it. But the consciousness is growing, especially in the last twelve months, with the pandemic. This really showed the value of data overall. But how to bring an organization on the way to make better use of data, to not only make data one of several aspects of the activity of the organization, but a real and strategic aspect of activity, this is, I think, the biggest challenge.
How do you see the future of Zetamind and what is your long-term goal?
At the moment we have an idea and a network and a vision. Now we try to find new collaborators, who are younger. To work not only on the technical aspects, but also on data culture and the approach to data reuse. So, I hope we find these people, these companies and collaborators. And for that we work together with the university of Lucerne, where there’s a master course on applied data science. We know the founder of this course and we collaborate. It’s a possibility for master’s students to work with our project and to learn about data value creation and data culture.
It has become rather difficult over the last two years for professionals to meet and informally discuss topics in their fields. Databooster is about bringing research and industry together so that new innovative projects in different data-intensive fields can be born. But how can we stimulate this exchange? The NLP Focus Group of the Databooster initiative (with Focus Group Leaders Mark Cieliebak, Philipp Thomann, Natalia Korchagina) addressed this challenge by organizing the first “Battle of NLP Ideas” workshop at the SwissText conference. The event was held on June 15, 2021 online.
About 50 NLP enthusiasts joined our virtual battle. The goal of this interactive session was to give stage to as many ideas as possible, multiplying the chances for the people with similar ideas to meet and possibly form an alliance. The final prize of the battle was a chance to turn your idea into an Innosuisse-funded project!
Our battle had several rounds. In the first round, the participants were split in small groups of 3 to 5 where everyone could pitch their idea to other member of the group in 10-20 seconds, and the most promising idea of each small group was selected by voting. In the next round, a small presentation of an idea was prepared by each group and then pitched in front of the members of other groups. The most promising ideas were discussed in more details with all participants. After three rounds and the final vote, we had our winning ideas:
• Fake-News detection • Topic Segmentation and Classification in Multi-topic Reports • Automatic Contract Generation
It has been an inspiring couple of hours. There is so much research potential and industry need in working NLP products in different domains, from journalism to ecology. To assist our winners in bringing their ideas to life, the focus group leaders organized follow-up meetings where the ideas were further developed, and their market potential was discussed in more details.
Fake News Detection API, capable to recognise fake news, has proven to be in huge demand. Three large Swiss media companies and two Swiss universities (FHNW and ZHAW) are discussing to collaborate. The plan is to start with an Innocheck which will be most likely followed by an Innosuisse application.
A first follow-up workshop on the Topic Segmentation idea showed that there is large interest from academia, but only limited significance to industry. Automatic contract generation did not receive enough support from the industrial partners after the first follow-up.
We wish all our participants to turn their ideas into real projects and keep our fingers crossed for the winners!
The next battle of NLP ideas will be fought at the upcoming SwissText conference in June2022. We are looking forward to seeing many fellow NLP enthusiasts joining the contest.
The 12th meeting of the expert group “Blockchain Technology in Interorganisational Collaboration” took place over lunch on the 29th of April.
First, the members were informed about the opportunities of the innovation process of the databooster. The innovation process gives the benefit of exploring and testing ideas together with experts in the field. Moreover, one can get support for project funding. The iterative process involves different steps such as scouting for ideas, setting up a call, shaping and re-shaping the challenge and ultimately setting up a deep-dive workshop (https://databooster.ch/expertise/).
After these introductory remarks, the expert group hosted Daniel Rutishauser from inacta AG to give an overview on the new DLT law and future trends in the blockchain sector. Daniel presented inacta’s hypotheses to four key areas of the blockchain space: crypto assets, token economies, DLT solutions, and DLT base layer. In particular in the area of crypto assets, Daniel explained that Switzerland has a competitive advantage due to the new favorable DLT law and he expects that many of the future crypto assets will be issued and traded in Switzerland. Besides many other topics, the current hype around NFTs (non-fungible tokens) and its effect on the digital art market gave rise to much discussion among the experts. The members could not agree on the fundamentals for the immense prices that this new market has realised. Considering the number of open questions, NFTs might be a topic that deserves a meeting for itself.
The online meeting was concluded without an apéro, but with many new insights on the blockchain sector gained.
Marco Zgraggen, Geschäftsführer, Sisag AG, Daniel Pfiffner, Geschäftsführer, ProSim GmbH Date of presentation: 16.03.21
Die Firmen Sisag AG, Remec AG und ProSim GmbH haben einen Bergbahnsimulator entwickelt, der es ermöglicht, Alpine Destinationen wie beispielsweise Skigebiete mit ihrer Infrastruktur in kurzer Zeit digital abzubilden und Entwicklungsmöglichkeiten zu testen und auszuwerten. Dabei geht es vor allem um Kapazität, Kosten des Betriebs und Verhalten der verschiedenen Gäste im Skigebiet.
Der Simulator hat dabei zwei Anwendungsgebiete. Einerseits ist dies die strategische Entwicklung der Bergbahngebiete. Dabei kann die Frage sein, was die ideale Dimensionierung eines zu ersetzenden Liftes ist und was die Auswirkungen der Dimensionierung auf das restliche Gebiet sind. Ebenso können neue Pistenführungen oder neue Anlagen und ihre Auswirkungen im Gebiet im Voraus getestet werden. Andererseits dient der Zwilling der operativen Entscheidungsunterstützung. Beispielsweise was passiert, wenn ich heute unter einer gewissen Anzahl Gäste eine weitere Piste öffne oder einen Lift schliesse, oder wie viele Kassen muss ich öffnen, damit die Wartezeit an der Talstation nicht zu gross wird.
1. What was the Challenge?
Es gab mehrere anspruchsvolle Entwicklungsschritte. Einerseits war es sicher die Zieldefinition des Projektes. Was sind die Fragestellungen, welche die Bergbahngebiete wirklich beschäftigen. Am Anfang wurde vor allem in Richtung Kapazitätsplanung entwickelt. Im Laufe des Projektes hat man festgestellt, dass die Kostenberechnungen ein ebenso wichtiger Teil für den Nutzen der Software ist.
Ein weiterer anspruchsvoller Schritt war, das Personenverhalten von verschiedenen Personengruppen im Gebiet abzubilden. Diese konnten durch agentenbasierte Simulation gut und generisch abgebildet werden.
2. By which Service-oriented Approach did we Solve it?
Der digitale Zwilling wird für jede Alpine Destination individuell gebaut und parametrisiert. Durch die vorgängige Entwicklung einer Bibliothek für Alpine Destinationen kann dies in kürzester Zeit realisiert werden. Die Software wird dem Betreiber anschliessend auf einer Plattform zur Verfügung gestellt.
3. What are our learnings?
Dies ist eine Umsetzung eines Digitalen Zwillings. Es wurde von der Zieldefinierung, über die Umsetzung, bis hin zu den Weiterentwicklungsmöglichkeiten und nächsten Schritten berichtet.
New structure, new logo, new concept: the expert group “Machine Learning Clinic” is a unique pool of expert knowledge. Our last meeting aimed to connect experts willing to share their knowledge with companies in need of expertise to push AI-projects forward. Despite the hype around AI and deep learning of the last years, only a few deployed solutions are running in industry. Why is this? What are the missing bricks? One of the missions of the ML-Clinic is to overcome this gap between lab and real-world applications.
During registration we identified needs and experts on the following hot topics:
Data Management
Vision Inspection
Cloud Integration
Hardware / Edge-Processing
During a 90min virtual meeting we connected people, exchanged experience, and brainstormed about new ideas. With the new open-innovation initiative www.databooster.ch and the support from Innosuisse there are many possibilities to support companies on their ML-journey.
In a familiar round we discussed about real cases from Roche, Sulzer, SBB and others. One common issue is data quality, availability and working with rare scenarios. How to deal with missing, wrong or corrupted data. How to train robust neural networks based on such datasets. There is no easy solution but there are more and more ideas how to deal with these common industrial issues.
Beside the deep technology discussions another highlight was the “non-virtual apéro package” which all participants received before the event. Even though we only communicated through Bytes over a glass fibre everyone had a real chilled beer and some nuts in their hands – what beer would be better to stimulate the real neurons than the AI beer: DEEPER
Overall a successful event and we hope you tune in for the next get together of the ML-Clinic!